
Can you swim in a data lake? No, the Data Lake works more like a newspaper. Interesting things happen all over the world and are documented by reporters on the ground. These reports, often in different languages, are presented in the newspaper in a uniform and appealing way. The benefits are obvious: without this structure, it would be impossible to get a comprehensive picture of the world. The DB Cargo Data Lake (hereinafter referred to as DBC Data Lake) fulfills precisely this task - but in the world of data. Here, "lines of code" take on the role of reporters. The DBC Data Lake belongs to DB Cargo and is part of a larger network that also includes Deutsche Bahn's other subsidiaries.
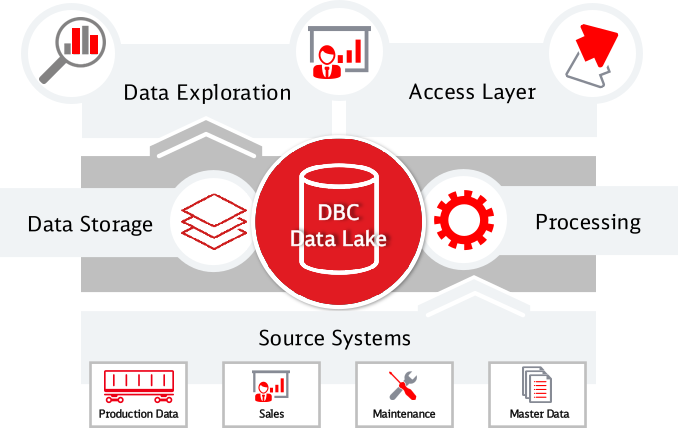
Diagram of the DBC Data Lake: Centralized data storage with connection to source systems such as production data, sales, maintenance and master data as well as functions for data exploration, processing and access layer.
How does the DBC Data Lake work?
Data generated within DB Cargo flows automatically into the DBC Data Lake, where it is networked, processed and standardized. This processed data is then available to employees to create analyses and reports. In this way, the Data Lake helps to broaden the view beyond the horizon and provide an up-to-date, uniform and comprehensive picture of the company.
Data flow and collection
But how does the data get into the DBC Data Lake and what information is collected? The DBC Data Lake obtains its data from various DB Cargo IT systems, such as production data, sales data, maintenance information and master data. There are also external data sources, such as reports on disruptions from DB InfraGo. Strict attention is paid to data protection: there is an information flow agreement for each data source, which must be approved. Personal data is either not recorded or is anonymized. The raw data is available in various formats, which are converted into a standardized format by the DBC Data Lake. Special data pipelines - the "reporters" in this analogy - are developed for each data source to automate the process. The process then runs largely independently and only needs to be maintained.
Speed and availability
Depending on the source, the data in the DBC Data Lake is available either on a daily basis or even within a few minutes. This prompt processing is often technically demanding. At the same time, the data lake also functions as a permanent archive in which new data is added daily. This combination of fast availability for frequently used data and efficient, cost-effective storage for infrequently used information makes the DBC Data Lake particularly valuable. This means that all users always have the same, up-to-date information. This helps to avoid errors in day-to-day work and to share knowledge across departmental boundaries - the classic "silo knowledge" of individual groups or departments is now a thing of the past.
How the company benefits from the DBC Data Lake
All departments at DB Cargo that deal with analyses, key figure calculations or forecasts benefit from the DBC Data Lake. Access to the main area is possible for all employees and only requires a one-off activation. The data stored there comprises the majority of the DBC Data Lake and does not contain any sensitive information. For specific requirements, there is also a protected area that can only be accessed by authorized persons. Here, too, the handling of sensitive data and data protection is clearly regulated and GDPR-compliant.
Employees use the DBC Data Lake interfaces to create dashboards, for example - interactive diagrams on internal websites that display time-dependent key figures. As these evaluations are directly connected to the data lake, they update automatically as soon as new data is available. Reports and key figures also draw their information automatically from the DBC Data Lake. One example of this is the provision of data for applications for state subsidies, such as single wagonload transport subsidies. In addition to automated access, the DBC Data Lake also enables spontaneous queries for users with SQL knowledge.
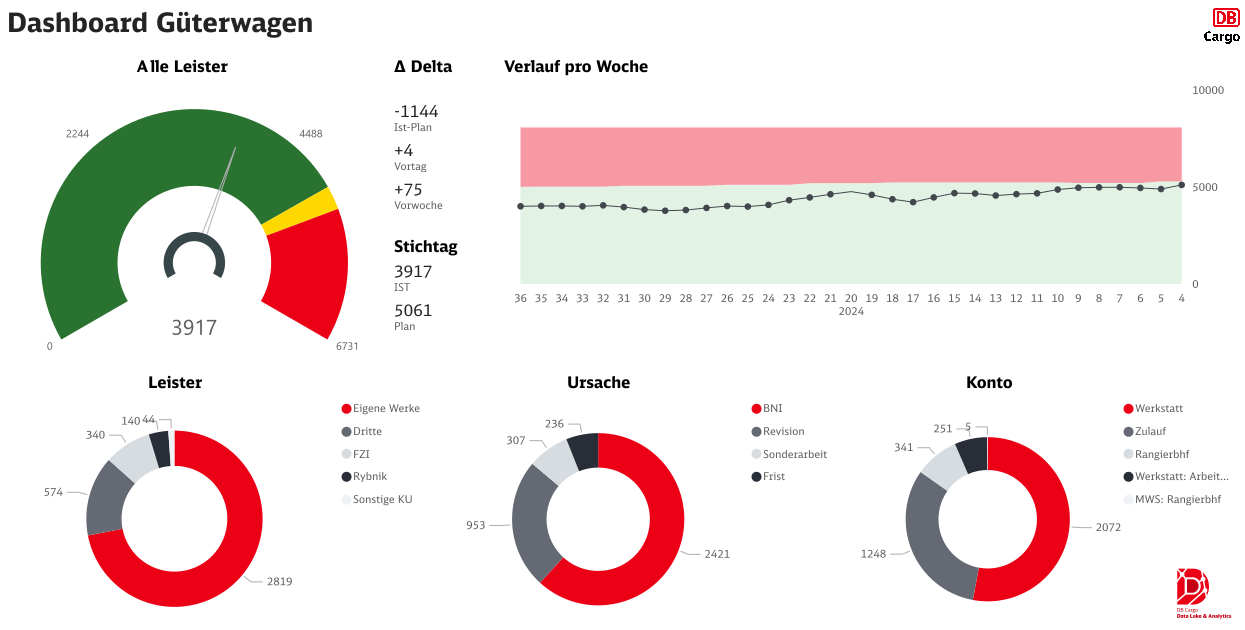
Dashboard for freight cars: Overview of current performance data, cause distribution and account allocations, including actual plan deviations and weekly history.
For forecasting purposes, the DBC Data Lake serves as an extensive data archive that is analyzed using statistical methods, machine learning and artificial intelligence to estimate future developments.
Into the future with the DBC Data Lake
The DBC Data Lake is already centralizing and standardizing information flows within the company. It replaces error-prone, decentralized systems cost-effectively and improves data protection at the same time. The DBC Data Lake paves the way for DB Cargo into the digital future and forms an indispensable basis for training AI models, as it provides historical data in a standardized form - an essential basis for well-founded forecasts using artificial intelligence
Sie haben Fragen? Wir helfen Ihnen gerne weiter!
DB Cargo AG








 Go
Go