Wenn Sie bereits eine konkrete Vorstellung zu Ihrem Transport haben, schreiben Sie uns eine Nachricht mit Ihrer unverbindlichen Transportanfrage.
Wer kann Transporte beauftragen und was ist die Mindestmenge?
Bitte beachten Sie, dass wir ausschließlich Transporte für Geschäftskund:innen durchführen und nahezu alles transportieren, was in mindestens einen Güterwagen oder Container / Wechselbrücke passt.
Wo finde ich Angebote rund um Jobs und Karriere bei DB Cargo?
Für Informationen rund um aktuelle Jobangebote, Praktika oder sonstige Personalfragen zur Karriere bei DB Cargo, besuchen Sie gerne unsere Website oder wenden Sie sich direkt an die Ansprechpartner:innen der jeweiligen Stellenausschreibung.
Im DB Cargo Data Lake laufen nicht nur rundum die Uhr Daten zusammen, sondern werden aufbereitet und archiviert.
Ende des Sliders
07.10.2024
Kann man im Data Lake schwimmen? Nein, der Data Lake funktioniert eher wie eine Zeitung. In der ganzen Welt geschehen interessante Dinge, die von Reportern vor Ort dokumentiert werden. Diese Berichte, oft in verschiedenen Sprachen, werden in der Zeitung einheitlich und ansprechend aufbereitet. Der Nutzen liegt auf der Hand: Ohne diese Struktur wäre es unmöglich, sich ein umfassendes Bild der Welt zu machen. Genau diese Aufgabe erfüllt der DB Cargo Data Lake (im weiteren Verlauf DBC Data Lake) – jedoch in der Datenwelt. Hier übernehmen „Codezeilen“ die Rolle der Reporter. Der DBC Data Lake gehört dabei zu DB Cargo und ist Teil eines größeren Netzwerks, das auch die anderen Tochterunternehmen der Deutschen Bahn umfasst.
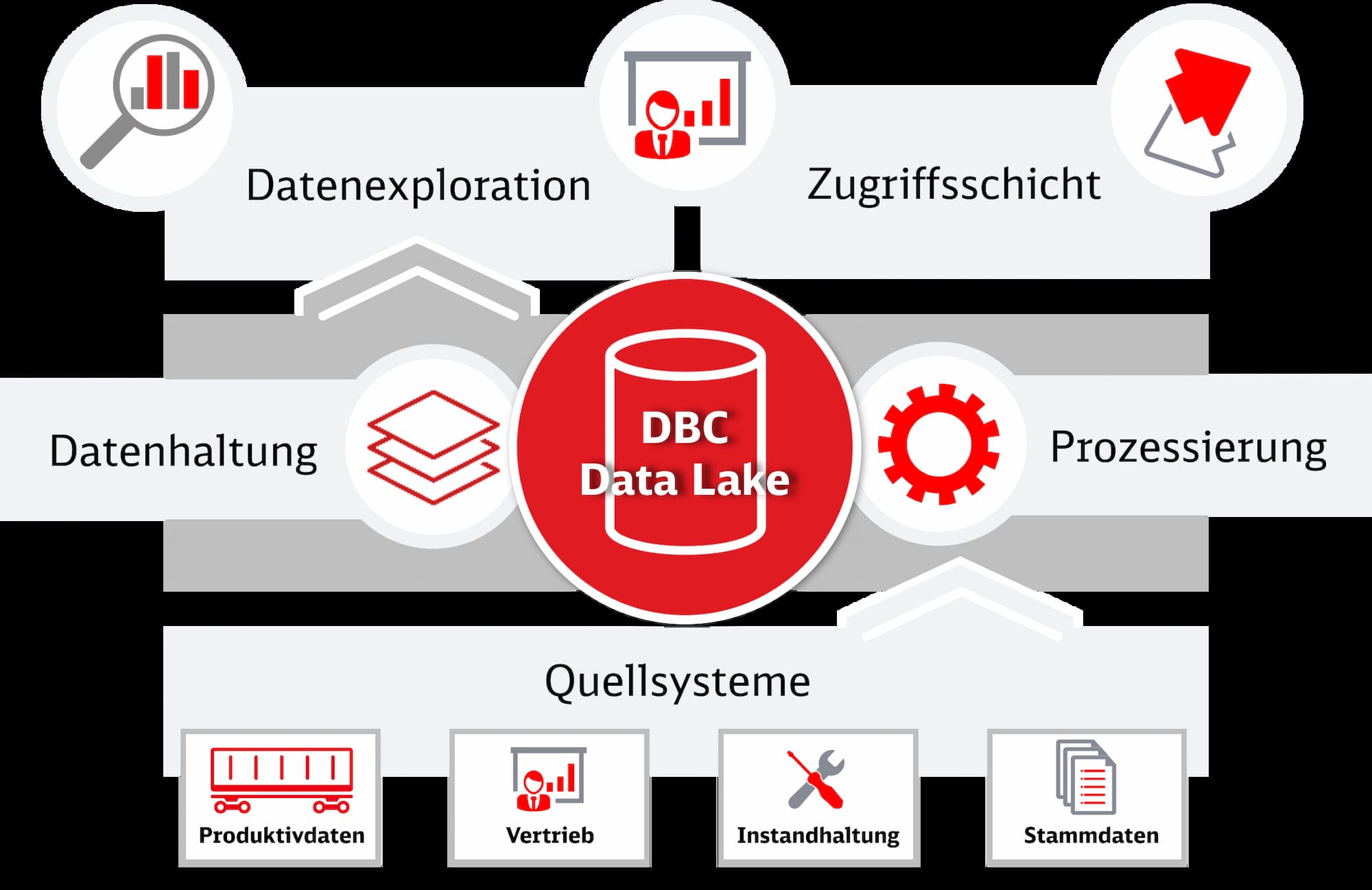
Schaubild des DBC Data Lakes: Zentralisierte Datenhaltung mit Anbindung an Quellsysteme wie Produktivdaten, Vertrieb, Instandhaltung und Stammdaten sowie Funktionen zur Datenexploration, Prozessierung und Zugriffsschicht.
Wie funktioniert der DBC Data Lake?
Daten, die innerhalb von DB Cargo generiert werden, fließen automatisiert in den DBC Data Lake, wo sie vernetzt, aufbereitet und standardisiert werden. Diese verarbeiteten Daten stehen dann den Mitarbeitenden zur Verfügung, um Analysen und Berichte zu erstellen. So hilft der Data Lake dabei, den Blick über den Tellerrand zu erweitern und ein aktuelles, einheitliches und umfassendes Bild des Unternehmens zu vermitteln.
Datenfluss und -erhebung
Doch wie gelangen die Daten in den DBC Data Lake und welche Informationen werden erfasst? Der DBC Data Lake bezieht seine Daten aus verschiedenen IT-Systemen von DB Cargo, wie etwa Produktivdaten, Vertriebsdaten, Instandhaltungsinformationen oder Stammdaten. Hinzu kommen externe Datenquellen, wie etwa Meldungen zu Störungen von DB InfraGo. Ein striktes Augenmerk liegt dabei auf dem Datenschutz: Zu jeder Datenquelle existiert eine Informationsflussvereinbarung, die genehmigt werden muss. Personenbezogene Daten werden entweder nicht erfasst oder anonymisiert. Die Rohdaten liegen in unterschiedlichen Formaten vor, welche durch den DBC Data Lake in ein standardisiertes Format überführt werden. Für jede Datenquelle werden spezielle Datenpipelines – in dieser Analogie also die „Reporter“ – entwickelt, die den Prozess automatisieren. Danach läuft dieser weitgehend selbstständig und muss nur noch gewartet werden.
Schnelligkeit und Verfügbarkeit
Je nach Quelle stehen die Daten im DBC Data Lake entweder tagesaktuell oder sogar innerhalb weniger Minuten zur Verfügung. Diese zeitnahe Verarbeitung ist oft technisch anspruchsvoll. Gleichzeitig fungiert der Data Lake auch als permanentes Archiv, in dem täglich neue Daten hinzukommen. Diese Kombination aus schneller Verfügbarkeit für häufig genutzte Daten und effizienter, kostengünstiger Speicherung für selten genutzte Informationen macht den DBC Data Lake besonders wertvoll. So haben alle Nutzenden stets den gleichen, aktuellen Informationsstand. Dies trägt dazu bei, Fehler im Arbeitsalltag zu vermeiden und Wissen über Abteilungsgrenzen hinweg zu teilen – das klassische „Silo-Wissen“ einzelner Gruppen oder Abteilungen ist damit passé.
So profitiert das Unternehmen vom DBC Data Lake
Alle Fachbereiche der DB Cargo, die sich mit Analysen, Kennzahlenberechnungen oder Prognosen beschäftigen, profitieren vom DBC Data Lake. Der Zugang zum Hauptbereich steht dabei allen Mitarbeitenden offen und erfordert lediglich eine einmalige Freischaltung. Die dort gespeicherten Daten umfassen den Großteil des DBC Data Lake und enthalten keine sensiblen Informationen. Für spezifische Anforderungen existiert zudem ein geschützter Bereich, auf den nur autorisierte Personen zugreifen können. Auch hier ist der Umgang mit den sensiblen Daten und der Datenschutz klar und DSGVO-konform geregelt.
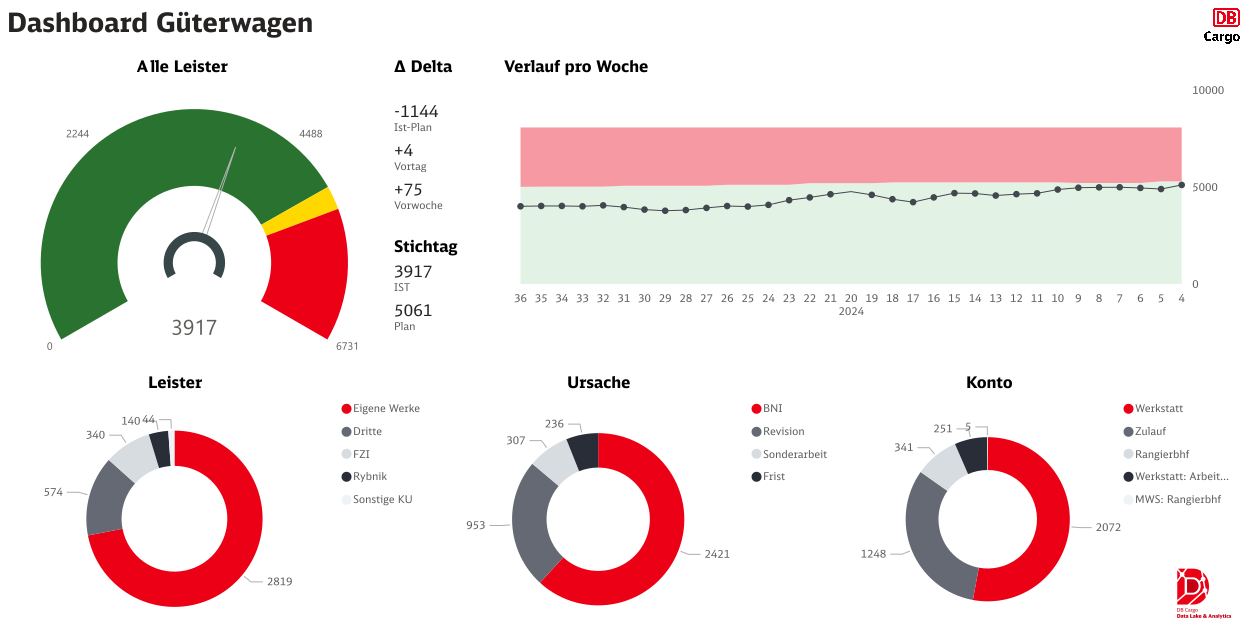
Mitarbeitende nutzen die Schnittstellen des DBC Data Lake, um beispielsweise Dashboards zu erstellen – interaktive Diagramme auf internen Webseiten, die zeitabhängige Kennzahlen darstellen. Da diese Auswertungen direkt mit dem Data Lake verbunden sind, aktualisieren sie sich automatisch, sobald neue Daten verfügbar sind. Berichte und Kennzahlen ziehen ihre Informationen ebenfalls automatisiert aus dem DBC Data Lake. Ein Beispiel dafür ist die Bereitstellung von Daten zur Beantragung staatlicher Fördermittel, wie der Einzelwagenverkehrsförderung. Neben dem automatisierten Zugriff ermöglicht der DBC Data Lake auch spontane Abfragen für Nutzer mit SQL-Kenntnissen.
Dashboard für Güterwagen: Übersicht über aktuelle Leistungsdaten, Ursachenverteilung und Kontozuordnungen, einschließlich Ist-Plan-Abweichungen und wöchentlichem Verlauf.
Für Prognosen dient der DBC Data Lake als umfangreiches Datenarchiv, das mit statistischen Methoden, maschinellem Lernen und künstlicher Intelligenz analysiert wird, um künftige Entwicklungen abzuschätzen.
Mit dem DBC Data Lake in die Zukunft
Bereits heute zentralisiert und vereinheitlicht der DBC Data Lake die Informationsflüsse innerhalb des Unternehmens. Er ersetzt fehleranfällige, dezentrale Systeme kostengünstig und verbessert zugleich den Datenschutz. Der DBC Data Lake öffnet DB Cargo den Weg in die digitale Zukunft und bildet eine unverzichtbare Grundlage für das Training von KI-Modellen, da er historische Daten in einheitlicher Form bereitstellt – eine essenzielle Basis für fundierte Prognosen durch künstliche Intelligenz.









 Weiter
Weiter